A Support Vector Machine is an algorithm that outputs a line separating two classes in a set of data.

An SVM will try to maximise the margin from the line to the nearest data points of the two classes.
If you use the scikit-learn library for training and predicting using the svm algorithm, you would use similar syntax as for the GaussianNB and in that matter the other machine learning algorithms.
In general when doing machine learning, you should reserve a part, about 10%, of your data to use as testing data, and that should not be used for training. Otherwise you would not get a realistic accuracy on your algorithm.
So we should split our training/testgin data into 4 varaibles, one set of features for training (an array, and in the case of svm, an array containing arrays that are the featuresw), one set of labels for those features, (the correct answer), similar variables to be used for testing.
from sklearn import svm
features_train = [[0, 0], [1, 1]]
labels_train = [0, 1]
clf = svm.SVC(kernel="linear")
clf.fit(features_train, labels_train)
pred = clf.predict([[2., 2.]])
If your data, however, is not separable linearly, lets say, that the data would look like this:

The data can not be separated by a line, but if you for instance add a new feature where the x is instead |x|, i.e. the absolute value of x, you could separate the data with a line.
A very powerful feature of support vector machines is to take a set of two dimensional data, and if it is not linearly separable, it uses something called Kernel tricks to transform the features into a multidimensional dataset, that is separable in order to get a solution
In the svm library you can also provide different kernels, or define your own. For instance, in the code example above you see that i use a linear kernel.
In the image below you see two decision boundaries that are produced on the same data but using two different kernels and another parameter called gamma, a linear to the left and rbf to the right (with gamma parameter of 1000).

The parameters are used when you create your svm classifier, ie. before you train it.
Another parameter you can use is called the C paramter. That can be set to indicate if you want a smooth border between the classes or classifier that classifies the training features correctly. The tradeoff can be that even though you could get a classfiier that is very correct on your training data with a high C, it might not be very good at generalizing your test data.

The gamma parameter tells how far a data point reaches in affecting the decision boundary. A low value means that you have a far reach, and a high value means a narrow reach. This means that with a high value you will get a very squiggly border, and a low value means you will get a more straight line because a single data point that otherwise would affect the border greatly, but might make the classifier not work well with the test data, is not affecting the line as much as it would be doing it only that dot would be the factor that adjusts the line. With a low value of the gamma parameter, you will also have the data points further away from the border to be taken into account when deciding where it shall be placed.
Overfitting
One thing we must always be aware of and try to avoid in machine learning is overftting. In the example below you see that the line to the left correctly classifies the green dots, but is very complicated. This can happen when you take the data too literal. If your algorithm produces a border similar to the one on the left instead of the one to the right, you are overfitting.

One way of reducing overfitting is through the use of you algorithms parameters.
Support Vector Machines work very well in complicated domains where there is a clear margin of separation. They do not perform efficiently in very large data sets, the training time increases cubically. They also do not work very well where there is a lot of noice in the data where the classes overlap (in that case a Naive Bayes classifier would be better)


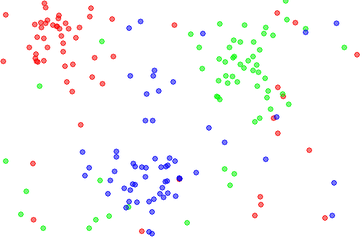 The Dataset
The Dataset 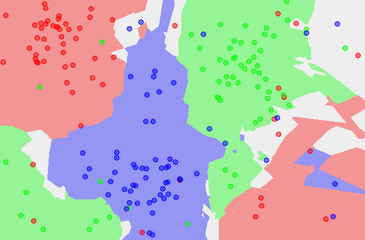 The 5NN classification map
The 5NN classification map
 If the answer was yes, we had an answer to our question if we shall go wakeboarding, and if it is not windy, we will ask another question: is it sunny? And if not, we won’t go wakeboarding, but if it is sunny, we’ll head to the lake.
If the answer was yes, we had an answer to our question if we shall go wakeboarding, and if it is not windy, we will ask another question: is it sunny? And if not, we won’t go wakeboarding, but if it is sunny, we’ll head to the lake.




